This blog describes on Configuring and running the Kafka from IBM BigInsights.
Apache Kafka is an open source that provides a publish-subscribe model for messaging system. Refer : https://kafka.apache.org/
I assume that you were aware of terminologies like Producer, Subscriber, Kafka Brokers, Topic and Partitions. Here, I will be focusing on creating multiple Brokers in BigInsights then create a topic and publish the messages from command line and consumer getting it from the Broker.
Environment: BigInsights 4.2
Step 1: Creating Kafka Brokers from Ambari
By default, Ambari will have one Kafka Broker configured. Based on your usecase, you may need to create multiple brokers.
Login to Ambari UI --> Click on Host and add the Kafka Broker to the node where you need to install Broker.

You can see multiple brokers running in Kafka UI.
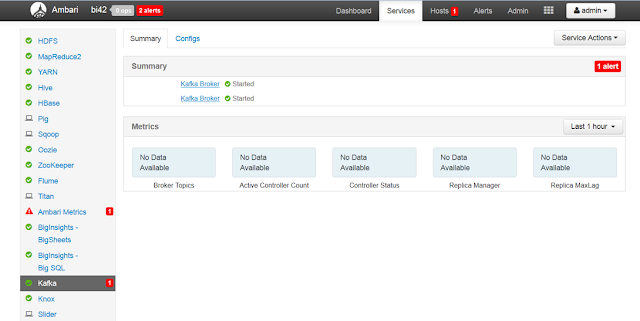
Step 2: Create a Topic
Login to one of the node where broker is running. Then create a topic.
cd /usr/iop/4.2.0.0/kafka/bin
su kafka -c "./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 -partitions 1 --topic CustomerOrder"

You can get the details of the topic using the below describe command.
su kafka -c "./kafka-topics.sh --describe --zookeeper localhost:2181 --topic CustomerOrder"

Step 3: Start the Producer
In the argument --broker-list, pass all the brokers that are running.
su kafka -c "./kafka-console-producer.sh --broker-list bi1.test.com:6667,bi2.test.com:6667 --topic CustomerOrder"
When you run the above command, it will be waiting for user input. You can pass a sample message
{"ID":99, "CUSTOMID":234,"ADDRESS":"12,5-7,westmead", "ORDERID":99, "ITEM":"iphone6", "COST":980}

Step 4: Start the Consumer
Open an other Linux terminal and start the consumer. It will display all the messages send to producer.
su kafka -c "./kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic CustomerOrder"

Thus, We are able to configure and perfom a sample pub-sub system using Kafka.
Apache Kafka is an open source that provides a publish-subscribe model for messaging system. Refer : https://kafka.apache.org/
I assume that you were aware of terminologies like Producer, Subscriber, Kafka Brokers, Topic and Partitions. Here, I will be focusing on creating multiple Brokers in BigInsights then create a topic and publish the messages from command line and consumer getting it from the Broker.
Environment: BigInsights 4.2
Step 1: Creating Kafka Brokers from Ambari
By default, Ambari will have one Kafka Broker configured. Based on your usecase, you may need to create multiple brokers.
Login to Ambari UI --> Click on Host and add the Kafka Broker to the node where you need to install Broker.

You can see multiple brokers running in Kafka UI.

Step 2: Create a Topic
Login to one of the node where broker is running. Then create a topic.
cd /usr/iop/4.2.0.0/kafka/bin
su kafka -c "./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 -partitions 1 --topic CustomerOrder"
You can get the details of the topic using the below describe command.
su kafka -c "./kafka-topics.sh --describe --zookeeper localhost:2181 --topic CustomerOrder"
Step 3: Start the Producer
In the argument --broker-list, pass all the brokers that are running.
su kafka -c "./kafka-console-producer.sh --broker-list bi1.test.com:6667,bi2.test.com:6667 --topic CustomerOrder"
When you run the above command, it will be waiting for user input. You can pass a sample message
{"ID":99, "CUSTOMID":234,"ADDRESS":"12,5-7,westmead", "ORDERID":99, "ITEM":"iphone6", "COST":980}
Step 4: Start the Consumer
Open an other Linux terminal and start the consumer. It will display all the messages send to producer.
su kafka -c "./kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic CustomerOrder"
Thus, We are able to configure and perfom a sample pub-sub system using Kafka.
14 comments:
Thanks for your interesting ideas.the information's in this blog is very much useful for me to improve my knowledge. Big Data Analytics Services Companies
Web Design and Development Company
Ecommerce Service Provider
Data Extraction Services
Payment Gateway Providers in India
Online Appointment Scheduling Software
Digital Marketing Services
Great blog
microstrategy courses
microstrategy training
Deep Learning Projects assist final year students with improving your applied Deep Learning skills rapidly while allowing you to investigate an intriguing point. Furthermore, you can include Deep Learning projects for final year into your portfolio, making it simpler to get a vocation, discover cool profession openings,
IBM Training in Bangalore
Amazing blog.Thanks for sharing such excellent information with us. keep sharing...
data analytics courses delhi
Well written articles like yours renews my faith in today's writers. The article is very informative. Thanks for sharing such beautiful information.
Best Data Migration tools
Penetration testing companies USA
What is Data Lake
Artificial Intelligence in Banking
What is Data analytics
Wonderful Blog.... Thanks for sharing with us...
Hadoop Training in Chennai
Hadoop Training in Bangalore
Big Data Onlie Course
Big Data Training in Coimbatore
Amazing Post. keep update more information.
Selenium Training in Bangalore
Selenium Training in Pune
Selenium Taining in Hyderabad
Selenium Training in Gurgaon
Selenium Training in Delhi
Intersting Information... keep sharing your blog
RPA Course in Chennai
Robotic Process Automation Training in Bangalore
thanks for share
artificial intelligence course aurangabad
Thanks for the great information
data science marketplace
Thanks for the post.
data science marketplace
Such a good post .thanks for sharing
Software testing training in Porur
Software testing training in chennai
Thanks for sharing nice information....
data science courses in aurangabad
Post a Comment